Kafka
01. Kafka资料
02. Kafka定义
Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
03. Kafka消息队列
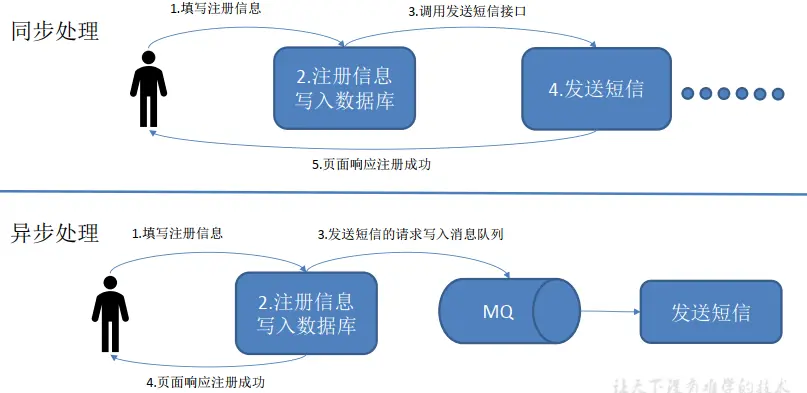
3.1. 传统消息队列的应用场景
3.2. 使用消息队列的好处
解耦
(类似Spring的IOC)
- 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
可恢复性
- 系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
缓冲
- 有助于控制和优化数据流经过系统的速度, 解决生产消息和消费消息的处理速度不一致的情况。
灵活性 & 峰值处理能力(削峰)
- 在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
异步通信
- 很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
3.4. 消息队列的两种模式
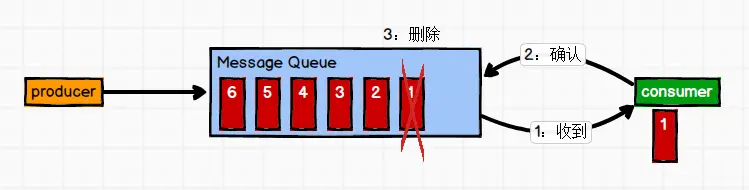
(1)点对点模式
一对一,消费者主动拉取数据,消息收到后消息清除
消息生产者生产消息发送到Queue中,然后消息消费者从Queue中取出并且消费消息。消息被消费以后, queue 中不再有存储,所以消息消费者不可能消费到已经被消费的消息。Queue 支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
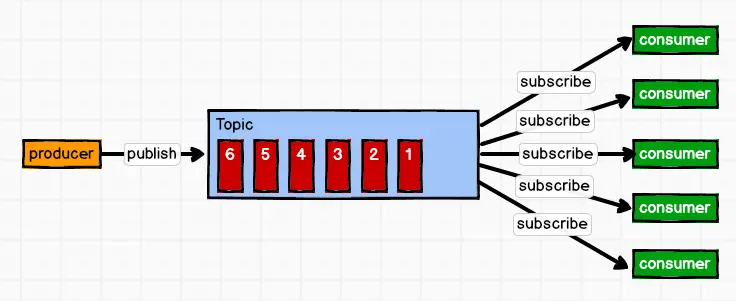
(2) 发布/订阅模式
一对多,消费者消费数据之后不会清除消息
消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。
04. Kafka_基础架构
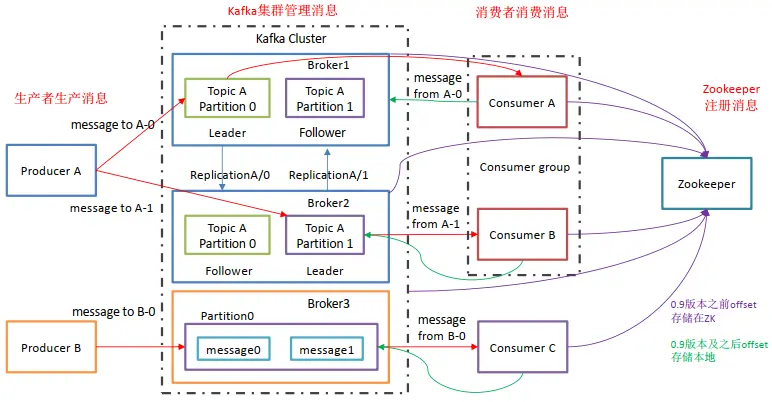
- Producer : 消息生产者,就是向 Kafka ;
- Consumer : 消息消费者,向 Kafka broker 取消息的客户端;
- Consumer Group (CG): 消费者组,由多个 consumer 组成。 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。 所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Broker :经纪人 一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker可以容纳多个 topic。
- Topic : 话题,可以理解为一个队列, 生产者和消费者面向的都是一个 topic;
- Partition: 为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列;
- Replica: 副本(Replication),为保证集群中的某个节点发生故障时, 该节点上的 partition 数据不丢失,且 Kafka仍然能够继续工作, Kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
- Leader: 每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 leader。
- Follower: 每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据的同步。 leader 发生故障时,某个 Follower 会成为新的 leader。
05. Kafka_快速入门
5.1. Quick Start
本次安装学习在Windows操作系统进行。(Linux版本的差别不大,运行脚本文件后缀从bat改为sh,配置路径改用Unix风格的)
Step 1: Download the code
下载代码并解压
解压到D:\Kafka`路径下,Kafka主目录文件为D:\Kafka\kafka_xxx`(下文的路径均用这个路径的相对路径表示)。
Step 2: Start the server
Kafka 用到 ZooKeeper 功能,所以要预先运行ZooKeeper,再启动kafka。
修改zookeeper日志文件的位置,创建新目录
D:\Kafka\zk-data修改
\conf\zookeeper.properties,将dataDir=/tmp/zookeeper改为dataDir=D:\Kafka\zk-data。在
D:\Kafka\kafka_xxx路径的上方输入cmd,进入命令窗口,启动zookeeperstart bin\windows\zookeeper-server-start.bat config\zookeeper.properties
修改kafka日志文件的位置,创建新目录``D:\Kafka\kafka-logs`
修改
\conf\server.properties,将log.dirs=/tmp/kafka-logs改为log.dirs=D:\Kafka\kafka-logs。在
D:\Kafka\kafka_xxx路径的上方输入cmd,进入命令窗口,启动kafka:start bin\windows\kafka-server-start.bat config\server.properties
关闭服务,
bin\windows\kafka-server-stop.bat和bin\windows\zookeeper-server-stop.bat。
Step 3: Create a topic
- 用单一partition和单一replica创建一个名为
test的topic:
1
bin \windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test- 查看已创建的topic,也就刚才创建的名为
test的topic:
1
bin \windows\kafka-topics.bat --list --zookeeper localhost:2181- 用单一partition和单一replica创建一个名为
Step 4: Start a producer
运行producer,并指定主题。然后输入几行文本,发至服务器:
1
2
3
4bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test
>hello, kafka.
>what a nice day!
>to be or not to be. that' s a question.Step 5: Start a consumer
运行consumer,指定消费者将要消费的topic。会发现消费者窗口将Step 4中输入的几行句子,标准输出。
1
2
3
4bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning
hello, kafka.
what a nice day!
to be or not to be. that' s a question.若你另启cmd,执行命令行
bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning来运行consumer,然后在Step 4中producer窗口输入一行句子,如I must admit, I can't help but feel a twinge of envy.,两个consumer也会同时输出I must admit, I can't help but feel a twinge of envy.。Step 6: Setting up a multi-broker cluster
如果需要多增加节点,则需要复制配置文件并进行修改。
首先,在
%KAFKA%\config\server.properties的基础上创建两个副本server-1.properties和server-2.properties。 copy config\server.properties config\server-1.properties
copy config\server.properties config\server-2.properties
打开新复制生成的两个副本,编辑如下属性
1
2
3
4
5
6
7
8
9config/server-1.properties:
broker.id=1
listeners=PLAINTEXT://127.0.0.1:9093
log.dir=D:\Kafka\kafka-logs-1
config/server-2.properties:
broker.id=2
listeners=PLAINTEXT://127.0.0.1:9094
log.dir=D:\Kafka\kafka-logs-2注意对于不同节点,
broker.id的设置不能相同。这个broker.id属性是集群中每个节点的唯一永久的名称。同时,我们必须重写端口和日志目录,只是因为我们在同一台机器上运行它们,并且我们希望阻止brokers试图在同一个端口上注册或覆盖彼此的数据。
目前已经启动了Zookeeper和单个kafka节点,配置结束后,启动两个新节点:
1
2start bin\windows\kafka-server-start.bat config\server-1.properties
start bin\windows\kafka-server-start.bat config\server-2.properties创建一个replication-factor为3的topic,名为
my-replicated-topic1
bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topicOK,现在我们有了一个集群,但是我们怎么知道哪个broker在做什么呢?那就运行
describe topics命令:1
2
3
4bin\windows\kafka-topics.bat --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 0
Replicas: 0,1,2 Isr: 0,1,2- “leader”是负责给定Partition的所有读写的节点。每个节点都可能成为Partition随机选择的leader。
- “replicas”是复制此Partition日志的节点列表,无论它们是leader还是当前处于存活状态。
- “isr”是一组 “in-sync” replicas。这是replicas列表的一个子集,它当前处于存活状态,并补充leader。
注意,在我的示例中,node 0是Topic唯一Partition的leader。(下面操作需要用到)
通过生产者向
my-replicated-topic这个主题发布一些信息:1
2
3bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic my-replicated-topic
There's sadness in your eyes, I don't want to say goodbye to you. Love is a big illusion, I should try to forget, but there's something left in m y head.通过消费者消费消息
1
2
3bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic
There's sadness in your eyes, I don't want to say goodbye to you. Love is a big illusion, I should try to forget, but there's something left in my head.如果当前某个partition的leader挂掉过后,将会发生什么呢?
先找出 Broker 0 的进程pid。
wmic process where “caption=’java.exe’ and commandline like ‘%server.properties%’” get processid,caption Caption ProcessId java.exe 7528
杀掉 Broker 0 的进程。
taskkill /pid 7528 /f 成功: 已终止 PID 为 7528 的进程。
通过
describe Topic命令查看当前主题的信息1
2
3
4bin\windows\kafka-topics.bat --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 1
Replicas: 0,1,2 Isr: 1,2可以发现原leader为node1,目前已被替换成它的ISR中的其中一个,并且 node 0 不在 in-sync replica 集合当中。
尽管原leader已逝,但原来消息依然可以接收。(注意,参数
--bootstrap-server localhost:9093,而不是--bootstrap-server localhost:9092)1
2
3bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9093 --from-beginning --topic my-replicated-topic
There's sadness in your eyes, I don't want to say goodbye to you. Love is a big illusion, I should try to forget, but there's something left in my head. I don't forget the way your kissing, the feeling 's so strong which is lasting for so long.
5.2. 配置文件server.properties
1 | |
06. 命令行操作Topic增删查
所有命令均为kafka-topics.bat
6.1. 查看 topic列表
1 | |
6.2. 创建 topic
1 | |
选项说明:
- –topic 定义 topic 名
- –replication-factor 定义副本数
- –partitions 定义分区数
为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列;
a broker = a kafka server a broker can contain N topic a topic can contain N partition a broker can contain a part of a topic (a broker can contain M(N>M) partition)
6.3. 删除 topic
1 | |
需要 server.properties 中设置 delete.topic.enable=true 否则只是标记删除。
6.4. 查看 topic 详情
1 | |
6.5. 修改分区数
1 | |
07. 命令行操作生产者消费者测试
7.1. 发送消息
1 | |
7.2. 消费消息
1 | |
- –from-beginning: 会把主题中以往所有的数据都读取出来。
08. Kafka工作流程
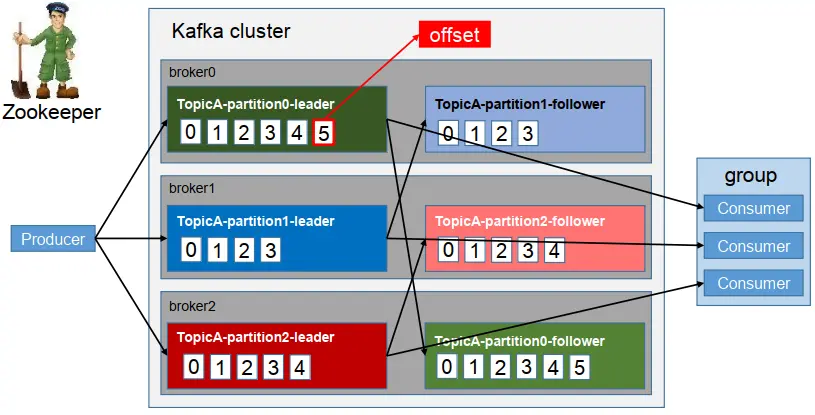
Kafka 中消息是以 topic 进行分类的, producer生产消息,consumer消费消息,都是面向 topic的。(从命令行操作看出)
1 | |
topic 是逻辑上的概念,而 partition 是物理上的概念,每个 partition 对应于一个 log 文件,该 log 文件中存储的就是 producer 生产的数据。(topic = N partition,partition = log)
Producer 生产的数据会被不断追加到该log 文件末端,且每条数据都有自己的 offset。 consumer组中的每个consumer, 都会实时记录自己消费到了哪个 offset,以便出错恢复时,从上次的位置继续消费。(producer -> log with offset -> consumer(s))
09. Kafka文件存储
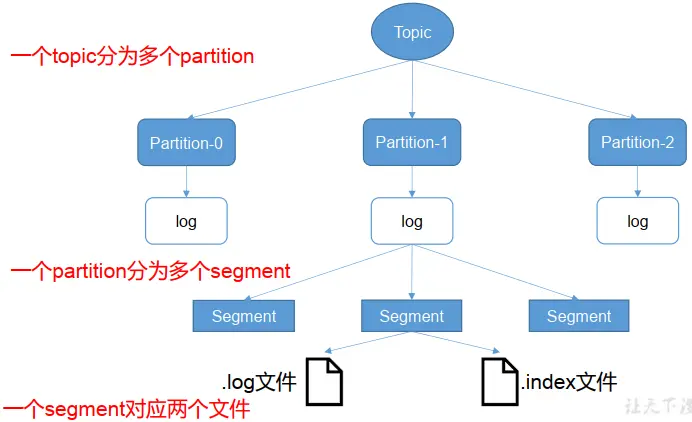
由于生产者生产的消息会不断追加到 log 文件末尾, 为防止 log 文件过大导致数据定位效率低下, Kafka 采取了**分片</和**索引</机制,将每个 partition 分为多个 segment。
每个 segment对应两个文件——“.index”文件和“.log”文件。 这些文件位于一个文件夹下, 该文件夹的命名规则为: topic 名称+分区序号。例如, first 这个 topic 有三个分区,则其对应的文件夹为 first-0,first-1,first-2。
1 | |
index 和 log 文件以当前 segment 的第一条消息的 offset 命名。下图为 index 文件和 log文件的结构示意图。
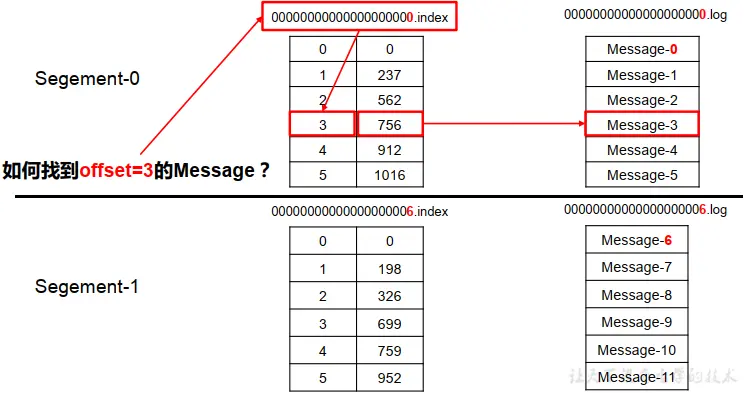
“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元数据指向对应数据文件中 message 的物理偏移地址。
segment 英 [ˈseɡmənt , seɡˈment] 美 [ˈseɡmənt , seɡˈment]
n.部分;份;片;段;(柑橘、柠檬等的)瓣;弓形;圆缺 v.分割;划分
10. Kskafa生产者
10.1. Kafka生产者分区策略
分区的原因
方便在集群中扩展,每个 Partition 可以通过调整以适应它所在的机器,而一个 topic又可以有多个 Partition 组成,因此整个集群就可以适应适合的数据了;
可以提高并发,因为可以以 Partition 为单位读写了。(联想到ConcurrentHashMap在高并发环境下读写效率比HashTable的高效)
分区的原则
我们需要将 producer 发送的数据封装成一个
ProducerRecord对象。- 指明 partition 的情况下,直接将指明的值直接作为 partiton 值;
- 没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值;
- 既没有 partition 值又没有 key 值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition值,也就是常说的 round-robin 算法。

10.2. Kafka可靠性保证
为保证 producer 发送的数据,能可靠的发送到指定的 topic, topic 的每个 partition 收到producer 发送的数据后,都需要向 producer 发送 ack(acknowledgement 确认收到),如果producer 收到 ack, 就会进行下一轮的发送,否则重新发送数据。
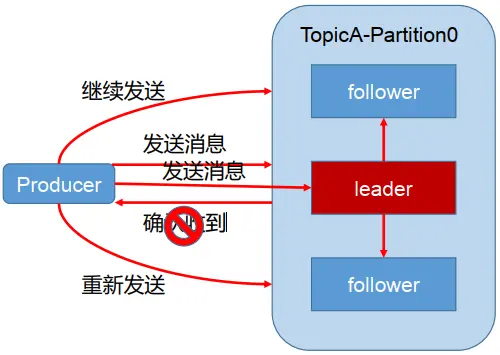
何时发送ack?
确保有follower与leader同步完成,leader再发送ack,这样才能保证leader挂掉之后,能在follower中选举出新的leader。
多少个follower同步完成之后发送ack?
- 半数以上的follower同步完成,即可发送ack继续发送重新发送
- 全部的follower同步完成,才可以发送ack
- 副本数据同步策略
| 序号 | 方案 | 优点 | 缺点 |
|---|---|---|---|
| 1 | 半数以上完成同步, 就发送 ack | 延迟低 | 选举新的 leader 时,容忍 n 台节点的故障,需要 2n+1 个副本。(如果集群有2n+1台机器,选举leader的时候至少需要半数以上即n+1台机器投票,那么能容忍的故障,最多就是n台机器发生故障)容错率:1/2 |
| 2 | 全部完成同步,才发送ack | 选举新的 leader 时, 容忍 n 台节点的故障,需要 n+1 个副本(如果集群有n+1台机器,选举leader的时候只要有一个副本就可以了)容错率:1 | 延迟高 |
Kafka 选择了第二种方案,原因如下:
- 同样为了容忍 n 台节点的故障,第一种方案需要 2n+1 个副本,而第二种方案只需要 n+1 个副本,而 Kafka 的每个分区都有大量的数据, 第一种方案会造成大量数据的冗余。
- 虽然第二种方案的网络延迟会比较高,但网络延迟对 Kafka 的影响较小。
ISR
采用第二种方案之后,设想以下情景: leader 收到数据,所有 follower 都开始同步数据,但有一个 follower,因为某种故障,迟迟不能与 leader 进行同步,那 leader 就要一直等下去,直到它完成同步,才能发送 ack。这个问题怎么解决呢?
Leader 维护了一个动态的 in-sync replica set (ISR),意为和 leader 保持同步的 follower 集合。当 ISR 中的 follower 完成数据的同步之后,就会给 leader 发送 ack。如果 follower长时间未向leader同步数据,则该follower将被踢出ISR,该时间阈值由
replica.lag.time.max.ms参数设定。 Leader 发生故障之后,就会从 ISR 中选举新的 leader。replica.lag.time.max.ms
DESCRIPTION: If a follower hasn’t sent any fetch requests or hasn’t consumed up to the leaders log end offset for at least this time, the leader will remove the follower from isr
TYPE: long
DEFAULT: 10000
ACk应答机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等 ISR 中的 follower 全部接收成功。所以 Kafka 为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,选择以下的配置。
acks 参数配置:
(1) ack=0
producer 不等待 broker 的 ack,这一操作提供了一个最低的延迟, broker 一接收到还没有写入磁盘就已经返回,当 broker 故障时有可能丢失数据;
(2) ack = 1
producer 等待 broker 的 ack, partition 的 leader 落盘成功后返回 ack,如果在 follower同步成功之前 leader 故障,那么将会丢失数据;
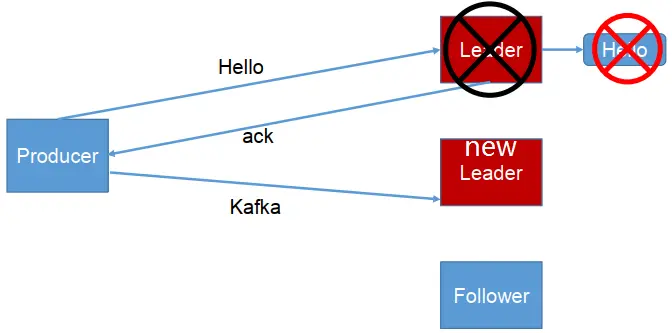
(3) ack = -1
producer 等待 broker 的 ack, partition 的 leader 和 ISR 的follower 全部落盘成功后才返回 ack。但是如果在 follower 同步完成后, broker 发送 ack 之前, leader 发生故障,那么会造成数据重复。
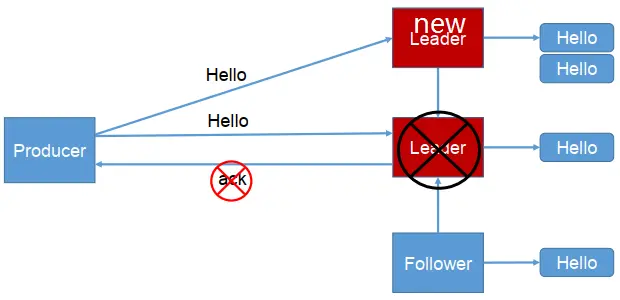
助记:返ACK前,0无落盘,1一落盘,-1全落盘,(落盘:消息存到本地)
acks
DESCRIPTION:
The number of acknowledgments the producer requires the leader to have received before considering a request complete. This controls the durability of records that are sent. The following settings are allowed:
acks=0If set to zero then the producer will not wait for any acknowledgment from the server at all. The record will be immediately added to the socket buffer and considered sent. No guarantee can be made that the server has received the record in this case, and the retries configuration will not take effect (as the client won’t generally know of any failures). The offset given back for each record will always be set to -1.acks=1This will mean the leader will write the record to its local log but will respond without awaiting full acknowledgement from all followers. In this case should the leader fail immediately after acknowledging the record but before the followers have replicated it then the record will be lost.acks=allThis means the leader will wait for the full set of in-sync replicas to acknowledge the record. This guarantees that the record will not be lost as long as at least one in-sync replica remains alive. This is the strongest available guarantee. This is equivalent to the acks=-1 setting.TYPE:string
DEFAULT:1
VALID VALUES:[all, -1, 0, 1]
10.3. 数据一致性问题
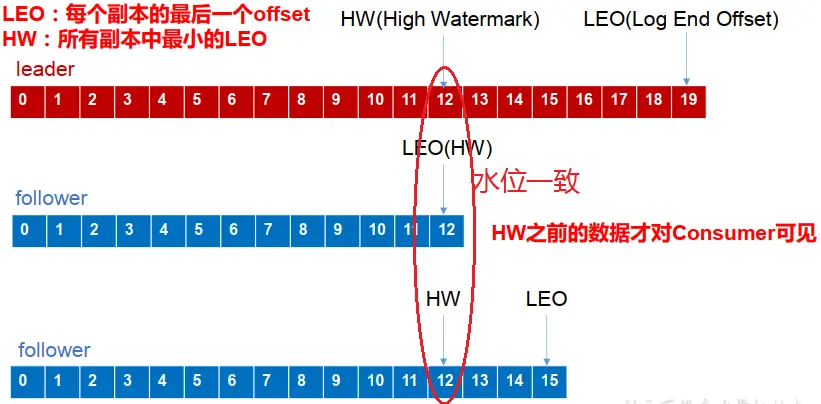
LEO:(Log End Offset)每个副本的最后一个offset
HW:(High Watermark)高水位,指的是消费者能见到的最大的 offset, ISR 队列中最小的 LEO
follower 故障:follower 发生故障后会被临时踢出 ISR,待该 follower 恢复后, follower 会读取本地磁盘记录的上次的 HW,并将 log 文件高于 HW 的部分截取掉,从 HW 开始向 leader 进行同步。等该 follower 的 LEO 大于等于该 Partition 的 HW,即 follower 追上 leader 之后,就可以重新加入 ISR 了。
leader 故障:leader 发生故障之后,会从 ISR 中选出一个新的 leader,之后,为保证多个副本之间的数据一致性, 其余的 follower 会先将各自的 log 文件高于 HW 的部分截掉,然后从新的 leader同步数据。
注意: 这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
10.4. ExactlyOnce
将服务器的 ACK 级别设置为-1(all),可以保证 Producer 到 Server 之间不会丢失数据,即 At Least Once 语义。
相对的,将服务器 ACK 级别设置为 0,可以保证生产者每条消息只会被发送一次,即 At Most Once 语义。
At Least Once 可以保证数据不丢失,但是不能保证数据不重复;相对的, At Most Once可以保证数据不重复,但是不能保证数据不丢失。 但是,对于一些非常重要的信息,比如说交易数据,下游数据消费者要求数据既不重复也不丢失,即 Exactly Once 语义。
- At least once—Messages are never lost but may be redelivered.
- At most once—Messages may be lost but are never redelivered.
- Exactly once—this is what people actually want, each message is delivered once and only once.
在 0.11 版本以前的 Kafka,对此是无能为力的,只能保证数据不丢失,再在下游消费者对数据做全局去重。对于多个下游应用的情况,每个都需要单独做全局去重,这就对性能造成了很大影响。
0.11 版本的 Kafka,引入了一项重大特性:幂等性。所谓的幂等性就是指 Producer 不论向 Server 发送多少次重复数据, Server 端都只会持久化一条。幂等性结合 At Least Once 语义,就构成了 Kafka 的 Exactly Once 语义。即:
1 | |
要启用幂等性,只需要将 Producer 的参数中 enable.idempotence 设置为 true 即可。 Kafka的幂等性实现其实就是将原来下游需要做的去重放在了数据上游。开启幂等性的 Producer 在初始化的时候会被分配一个 PID,发往同一 Partition 的消息会附带 Sequence Number。而Broker 端会对<PID, Partition, SeqNumber>做缓存,当具有相同主键的消息提交时, Broker 只会持久化一条。
但是 PID 重启就会变化,同时不同的 Partition 也具有不同主键,所以幂等性无法保证跨分区跨会话的 Exactly Once。
enable.idempotence
DESCRIPTION:When set to ‘true’, the producer will ensure that exactly one copy of each message is written in the stream. If ‘false’, producer retries due to broker failures, etc., may write duplicates of the retried message in the stream. This is set to ‘false’ by default. Note that enabling idempotence requires
max.in.flight.requests.per.connectionto be set to 1 andretriescannot be zero. Additionally acks must be set to ‘all’. If these values are left at their defaults, we will override the default to be suitable. If the values are set to something incompatible with the idempotent producer, a ConfigException will be thrown.TYPE:boolean
DEFAULT:false
11.Kafka消费者
11.1. 消费方式
consumer 采用 pull(拉) 模式从 broker 中读取数据。
push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由 broker 决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成 consumer 来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而 pull 模式则可以根据 consumer 的消费能力以适当的速率消费消息。
pull 模式不足之处是,如果 kafka 没有数据,消费者可能会陷入循环中, 一直返回空数据。 针对这一点, Kafka 的消费者在消费数据时会传入一个时长参数 timeout,如果当前没有数据可供消费, consumer 会等待一段时间之后再返回,这段时长即为 timeout。
11.2. 分区分配策略
一个 consumer group 中有多个 consumer,一个 topic 有多个 partition,所以必然会涉及到 partition 的分配问题,即确定那个 partition 由哪个 consumer 来消费。
Kafka 有两种分配策略:
- round-robin循环
- range
partition.assignment.strategy
Select between the “range” or “roundrobin” strategy for assigning分配 partitions to consumer streams.
The round-robin partition assignor lays out规划 all the available partitions and all the available consumer threads. It then proceeds to do接着做 a round-robin assignment from partition to consumer thread. If the subscriptions订阅 of all consumer instances are identical完全同样的, then the partitions will be uniformly 均匀地distributed. (i.e.也就是说, the partition ownership counts will be within a delta of exactly one across all consumer threads.) Round-robin assignment is permitted only if:
- Every topic has the same number of streams within a consumer instance
- The set of subscribed topics is identical for every consumer instance within the group.
Range partitioning works on a per-topic basis. For each topic, we lay out the available partitions in numeric order and the consumer threads in lexicographic词典式的 order. We then divide the number of partitions by the total number of consumer streams (threads) to determine the number of partitions to assign to each consumer. If it does not evenly divide, then the first few consumers will have one extra partition.
DEFAULT:range
(1)Round Robin
关于Roudn Robin重分配策略,其主要采用的是一种轮询的方式分配所有的分区,该策略主要实现的步骤如下。这里我们首先假设有三个topic:t0、t1和t2,这三个topic拥有的分区数分别为1、2和3,那么总共有六个分区,这六个分区分别为:t0-0、t1-0、t1-1、t2-0、t2-1和t2-2。这里假设我们有三个consumer:C0、C1和C2,它们订阅情况为:C0订阅t0,C1订阅t0和t1,C2订阅t0、t1和t2。那么这些分区的分配步骤如下:
- 首先将所有的partition和consumer按照字典序进行排序,所谓的字典序,就是按照其名称的字符串顺序,那么上面的六个分区和三个consumer排序之后分别为:
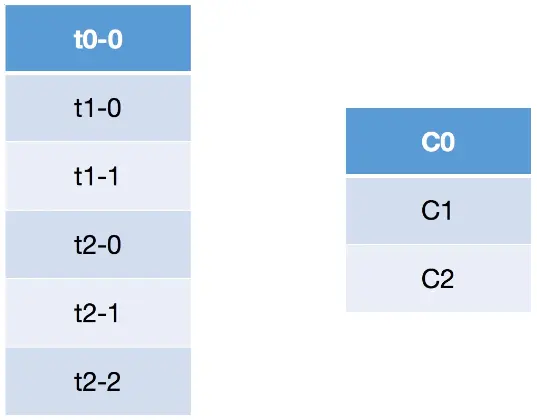
- 然后依次以按顺序轮询的方式将这六个分区分配给三个consumer,如果当前consumer没有订阅当前分区所在的topic,则轮询的判断下一个consumer:
- 尝试将t0-0分配给C0,由于C0订阅了t0,因而可以分配成功;
- 尝试将t1-0分配给C1,由于C1订阅了t1,因而可以分配成功;
- 尝试将t1-1分配给C2,由于C2订阅了t1,因而可以分配成功;
- 尝试将t2-0分配给C0,由于C0没有订阅t2,因而会轮询下一个consumer;
- 尝试将t2-0分配给C1,由于C1没有订阅t2,因而会轮询下一个consumer;
- 尝试将t2-0分配给C2,由于C2订阅了t2,因而可以分配成功;
- 同理由于t2-1和t2-2所在的topic都没有被C0和C1所订阅,因而都不会分配成功,最终都会分配给C2。
- 按照上述的步骤将所有的分区都分配完毕之后,最终分区的订阅情况如下:

从上面的步骤分析可以看出,轮询的策略就是简单的将所有的partition和consumer按照字典序进行排序之后,然后依次将partition分配给各个consumer,如果当前的consumer没有订阅当前的partition,那么就会轮询下一个consumer,直至最终将所有的分区都分配完毕。但是从上面的分配结果可以看出,轮询的方式会导致每个consumer所承载的分区数量不一致,从而导致各个consumer压力不均一。
(2)Range
所谓的Range重分配策略,就是首先会计算各个consumer将会承载的分区数量,然后将指定数量的分区分配给该consumer。这里我们假设有两个consumer:C0和C1,两个topic:t0和t1,这两个topic分别都有三个分区,那么总共的分区有六个:t0-0、t0-1、t0-2、t1-0、t1-1和t1-2。那么Range分配策略将会按照如下步骤进行分区的分配:
- 需要注意的是,Range策略是按照topic依次进行分配的,比如我们以t0进行讲解,其首先会获取t0的所有分区:t0-0、t0-1和t0-2,以及所有订阅了该topic的consumer:C0和C1,并且会将这些分区和consumer按照字典序进行排序;
- 然后按照平均分配的方式计算每个consumer会得到多少个分区,如果没有除尽,则会将多出来的分区依次计算到前面几个consumer。比如这里是三个分区和两个consumer,那么每个consumer至少会得到1个分区,而3除以2后还余1,那么就会将多余的部分依次算到前面几个consumer,也就是这里的1会分配给第一个consumer,总结来说,那么C0将会从第0个分区开始,分配2个分区,而C1将会从第2个分区开始,分配1个分区;
- 同理,按照上面的步骤依次进行后面的topic的分配。
- 最终上面六个分区的分配情况如下:
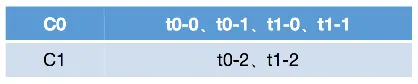
可以看到,如果按照Range分区方式进行分配,其本质上是依次遍历每个topic,然后将这些topic的分区按照其所订阅的consumer数量进行平均的范围分配。这种方式从计算原理上就会导致排序在前面的consumer分配到更多的分区,从而导致各个consumer的压力不均衡。
TODO:我的问题:topic分多个partition,有些custom根据上述策略,分到topic的部分partition,难道不是要全部partition吗?是不是还要按照相同策略多分配多一次?
11.3. 消费者offset的存储
由于 consumer 在消费过程中可能会出现断电宕机等故障, consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。
Kafka 0.9 版本之前, consumer 默认将 offset 保存在 Zookeeper 中,从 0.9 版本开始,consumer 默认将 offset 保存在 Kafka 一个内置的 topic 中,该 topic 为__consumer_offsets。
- 修改配置文件 consumer.properties,
exclude.internal.topics=false。 - 读取 offset
- 0.11.0.0 之前版本 -
bin/kafka-console-consumer.sh --topic __consumer_offsets --zookeeper hadoop102:2181 --formatter "kafka.coordinator.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning - 0.11.0.0 及之后版本 -
bin/kafka-console-consumer.sh --topic __consumer_offsets --zookeeper hadoop102:2181 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning
- 0.11.0.0 之前版本 -
TODO:上机实验
11.4. 消费者组案例
(1) 需求
测试同一个消费者组中的消费者, 同一时刻只能有一个消费者消费。
(2) 操作步骤
1.修改%KAFKA_HOME\config\consumer.properties%文件中的group.id属性。
1 | |
2.打开两个cmd,分别启动两个消费者。(以%KAFKA_HOME\config\consumer.properties%作配置参数)
1 | |
3.再打开一个cmd,启动一个生产者。
1 | |
4.在生产者窗口输入消息,观察两个消费者窗口。会发现两个消费者窗口中,只有一个才会弹出消息。
12. Kafka高效读写&ZK作用
12.1. 顺序写磁盘
Kafka 的 producer 生产数据,要写入到 log 文件中,写的过程是一直追加到文件末端,为顺序写。 官网有数据表明,同样的磁盘,顺序写能到 600M/s,而随机写只有 100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
12.2. 零复制技术
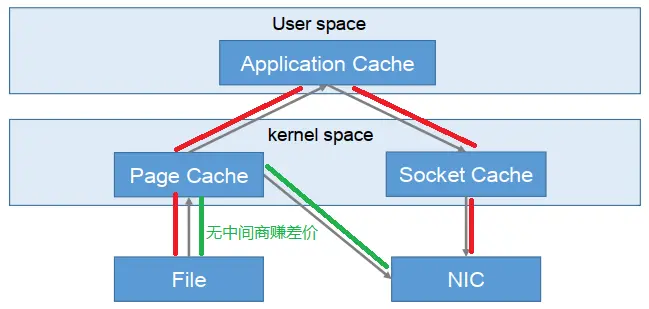
- NIC network interface controller 网络接口控制器
12.3. zk在kafka中的作用
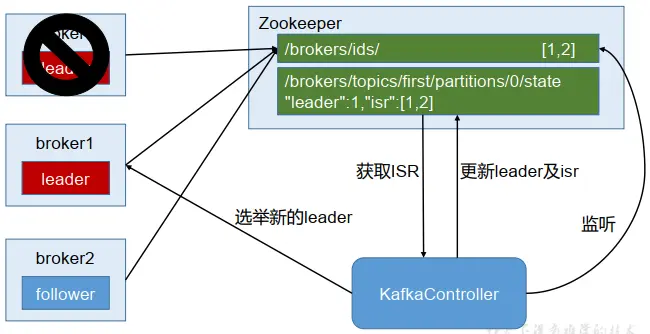
Kafka 集群中有一个 broker 会被选举为 Controller,负责管理集群 broker 的上下线,所有 topic 的分区副本分配和 leader 选举等工作。Reference
Controller 的管理工作都是依赖于 Zookeeper 的。
以下为 partition 的 leader 选举过程:
14.Kafka高级_事务
Kafka 从 0.11 版本开始引入了事务支持。事务可以保证 Kafka 在 Exactly Once 语义的基础上,生产和消费可以跨分区和会话,要么全部成功,要么全部失败。
14.1. Producer 事务
为了实现跨分区跨会话的事务,需要引入一个全局唯一的 Transaction ID,并将 Producer 获得的PID 和Transaction ID 绑定。这样当Producer 重启后就可以通过正在进行的 TransactionID 获得原来的 PID。
为了管理 Transaction, Kafka 引入了一个新的组件 Transaction Coordinator。 Producer 就是通过和 Transaction Coordinator 交互获得 Transaction ID 对应的任务状态。 Transaction Coordinator 还负责将事务所有写入 Kafka 的一个内部 Topic,这样即使整个服务重启,由于事务状态得到保存,进行中的事务状态可以得到恢复,从而继续进行。
14.2. Consumer 事务
上述事务机制主要是从 Producer 方面考虑,对于 Consumer 而言,事务的保证就会相对较弱,尤其时无法保证 Commit 的信息被精确消费。这是由于 Consumer 可以通过 offset 访问任意信息,而且不同的 Segment File 生命周期不同,同一事务的消息可能会出现重启后被删除的情况。
15.Kafka API
15.1. Producer API
15.1.1. 消息发送流程
Kafka 的 Producer 发送消息采用的是异步发送的方式。在消息发送的过程中,涉及到了两个线程——main 线程和 Sender 线程,以及一个线程共享变量——RecordAccumulator。 main 线程将消息发送给 RecordAccumulator, Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka broker。
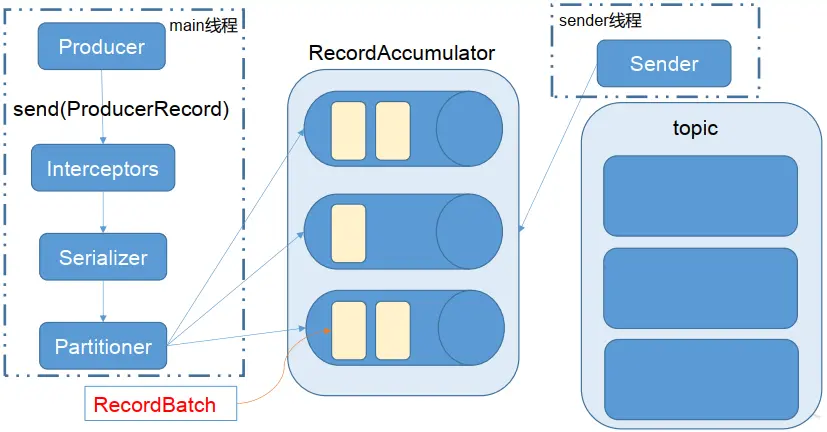
相关参数:
- batch.size: 只有数据积累到 batch.size 之后, sender 才会发送数据。
- linger.ms: 如果数据迟迟未达到 batch.size, sender 等待 linger.time 之后就会发送数据。
15.1.2. 异步发送API
导入依赖
1 | |
- 编写代码
需要用到的类:
- KafkaProducer:需要创建一个生产者对象,用来发送数据
- ProducerConfig:获取所需的一系列配置参数
- ProducerRecord:每条数据都要封装成一个 ProducerRecord 对象
(1) 不带回调函数
1 | |
(2) 带回调函数
回调函数会在 producer 收到 ack 时调用,为异步调用, 该方法有两个参数,分别是 RecordMetadata 和 Exception,如果 Exception 为 null,说明消息发送成功,如果Exception 不为 null,说明消息发送失败。
注意:消息发送失败会自动重试,不需要我们在回调函数中手动重试。
1 | |
15.1.3. 同步发送API
同步发送的意思就是,一条消息发送之后,会阻塞当前线程, 直至返回 ack。
由于 send 方法返回的是一个 Future 对象,根据 Futrue 对象的特点,我们也可以实现同步发送的效果,只需在调用 Future 对象的 get 方发即可。
1 | |
15.1.4. 生产者分区策略
ProducerRecord类有许多构造函数,其中一个参数partition可指定分区
TODO:根据策略阐述,亲自设计分区策略测试,range和round-robin间的区别
15.1.5. 带自定义分区器
1 | |
具体内容填写可参考默认分区器org.apache.kafka.clients.producer.internals.DefaultPartitioner
然后Producer配置中注册使用
1 | |
15.2. Consumer API
Consumer 消费数据时的可靠性是很容易保证的,因为数据在 Kafka 中是持久化的,故不用担心数据丢失问题。
由于 consumer 在消费过程中可能会出现断电宕机等故障, consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。
所以 offset 的维护是 Consumer 消费数据是必须考虑的问题。
15.2.1. 自动提交offset
- KafkaConsumer: 需要创建一个消费者对象,用来消费数据
- ConsumerConfig: 获取所需的一系列配置参数
- ConsuemrRecord: 每条数据都要封装成一个 ConsumerRecord 对象
为了使我们能够专注于自己的业务逻辑, Kafka 提供了自动提交 offset 的功能。
自动提交 offset 的相关参数:
- enable.auto.commit:是否开启自动提交 offset 功能
- auto.commit.interval.ms:自动提交 offset 的时间间隔
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
public class CustomConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "127.0.0.1:9092");
props.put("group.id", "abc");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("test"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
}
15.2.2. 手动提交offset
虽然自动提交 offset 十分便利,但由于其是基于时间提交的, 开发人员难以把握offset 提交的时机。因此 Kafka 还提供了手动提交 offset 的 API。
手动提交 offset 的方法有两种:
- commitSync(同步提交)
- commitAsync(异步提交)
两者的相同点是,都会将本次 poll 的一批数据最高的偏移量提交;
不同点是,commitSync 阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而 commitAsync 则没有失败重试机制,故有可能提交失败。
(1) 同步提交offset
由于同步提交 offset 有失败重试机制,故更加可靠,以下为同步提交 offset 的示例。
1 | |
(2) 异步提交offset
虽然同步提交 offset 更可靠一些,但是由于其会阻塞当前线程,直到提交成功。因此吞吐量会收到很大的影响。因此更多的情况下,会选用异步提交 offset 的方式。
1 | |
(3) 数据漏消费和重复消费分析
无论是同步提交还是异步提交 offset,都有可能会造成数据的漏消费或者重复消费。先提交 offset 后消费,有可能造成数据的漏消费;而先消费后提交 offset,有可能会造成数据的重复消费。
15.2.3. 自定义存储 offset
Kafka 0.9 版本之前, offset 存储在 zookeeper, 0.9 版本及之后,默认将 offset 存储在 Kafka的一个内置的 topic 中。除此之外, Kafka 还可以选择自定义存储 offset。
offset 的维护是相当繁琐的, 因为需要考虑到消费者的 Rebalace。
当有新的消费者加入消费者组、 已有的消费者推出消费者组或者所订阅的主题的分区发生变化,就会触发到分区的重新分配,重新分配的过程叫做 Rebalance。
消费者发生 Rebalance 之后,每个消费者消费的分区就会发生变化。因此消费者要首先获取到自己被重新分配到的分区,并且定位到每个分区最近提交的 offset 位置继续消费。
要实现自定义存储 offset,需要借助 ConsumerRebalanceListener, 以下为示例代码,其中提交和获取 offset 的方法,需要根据所选的 offset 存储系统自行实现。(可将offset存入MySQL数据库)
1 | |
15.2.4. 保存offset读取问题
1 | |
enable.auto.commit
If true the consumer’s offset will be periodically committed in the background.
TYPE:boolean
DEFAULT:true
PS.我将Offset提交类比成数据库事务的提交。
16.自定义拦截器API
16.1. 拦截器原理
Producer 拦截器(interceptor)是在 Kafka 0.10 版本被引入的,主要用于实现 clients 端的定制化控制逻辑。
对于 producer 而言, interceptor 使得用户在消息发送前以及 producer 回调逻辑前有机会对消息做一些定制化需求,比如修改消息等。同时, producer 允许用户指定多个 interceptor按序作用于同一条消息从而形成一个拦截链(interceptor chain)。 Intercetpor 的实现接口是org.apache.kafka.clients.producer.ProducerInterceptor,其定义的方法包括:
configure(configs):获取配置信息和初始化数据时调用。onSend(ProducerRecord):该方法封装进 KafkaProducer.send 方法中,即它运行在用户主线程中。 Producer 确保在消息被序列化以及计算分区前调用该方法。 用户可以在该方法中对消息做任何操作,但最好保证不要修改消息所属的 topic 和分区, 否则会影响目标分区的计算。onAcknowledgement(RecordMetadata, Exception):该方法会在消息从 RecordAccumulator 成功发送到 Kafka Broker 之后,或者在发送过程中失败时调用。 并且通常都是在 producer 回调逻辑触发之前。 onAcknowledgement 运行在producer 的 IO 线程中,因此不要在该方法中放入很重的逻辑,否则会拖慢 producer 的消息发送效率。close():关闭 interceptor,主要用于执行一些资源清理工作
如前所述, interceptor 可能被运行在多个线程中,因此在具体实现时用户需要自行确保线程安全。另外倘若指定了多个 interceptor,则 producer 将按照指定顺序调用它们,并仅仅是捕获每个 interceptor 可能抛出的异常记录到错误日志中而非在向上传递。这在使用过程中要特别留意。
16.2. 自定义拦截器(代码)
(1) 需求
实现一个简单的双 interceptor 组成的拦截链。
第一个 interceptor 会在消息发送前将时间戳信息加到消息 value 的最前部;
第二个 interceptor 会在消息发送后更新成功发送消息数或失败发送消息数。
(2) 案例实操
- 增加时间戳拦截器
1 | |
- 增加时间戳拦截器
统计发送消息成功和发送失败消息数,并在 producer 关闭时打印这两个计数器
1 | |
- producer 主程序
1 | |
16.3. 拦截器(案例测试)

17. Kafka面试题
- Kafka 中的 ISR(InSyncRepli)、 OSR(OutSyncRepli)、 AR(AllRepli)代表什么?
- Kafka 中的 HW、 LEO 等分别代表什么?
- Kafka 中是怎么体现消息顺序性的?
- Kafka 中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?
- Kafka 生产者客户端的整体结构是什么样子的?使用了几个线程来处理?分别是什么?
- “消费组中的消费者个数如果超过 topic 的分区,那么就会有消费者消费不到数据”这句 话是否正确?
- 消费者提交消费位移时提交的是当前消费到的最新消息的 offset 还是 offset+1?
- 有哪些情形会造成重复消费?
- 那些情景会造成消息漏消费?
- 当你使用 kafka-topics.sh 创建(删除)了一个 topic 之后, Kafka 背后会执行什么逻辑?
- 会在 zookeeper 中的/brokers/topics 节点下创建一个新的 topic 节点,如:/brokers/topics/first
- 触发 Controller 的监听程序
- kafka Controller 负责 topic 的创建工作,并更新 metadata cache
- topic 的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
- topic 的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?
- Kafka 有内部的 topic 吗?如果有是什么?有什么所用?
- Kafka 分区分配的概念?
- 简述 Kafka 的日志目录结构?
- 如果我指定了一个 offset, Kafka Controller 怎么查找到对应的消息?
- 聊一聊 Kafka Controller 的作用?
- Kafka 中有那些地方需要选举?这些地方的选举策略又有哪些?
- 失效副本是指什么?有那些应对措施?
- Kafka 的哪些设计让它有如此高的性能?
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!